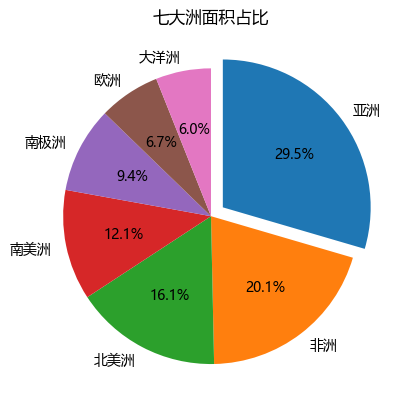
序言
在深度学习的浩瀚征途中,调试无疑是每位探索者必经的试炼场。深度学习模型以其复杂性和高维性著称,从数据预处理到模型架构设计,再到训练调优,每一个环节都可能潜藏着导致性能不佳的“陷阱”。因此,掌握一套高效实用的调试策略,对于加速模型收敛、提升泛化能力至关重要。本文旨在概述深度学习中的关键调试策略,帮助读者在实战中更加游刃有余地应对挑战。
概要
- 数据检查:
- 首先确保数据质量,检查是否存在缺失值、异常值或标签错误。
- 数据增强和归一化处理也是提升模型鲁棒性的有效手段。
- 模型简化:
- 从最简单的模型开始,逐步增加复杂度。
- 这有助于快速定位问题是否源于模型结构本身,还是其他外部因素。
- 梯度监控:
- 监控梯度值的变化,避免梯度消失或爆炸问题。
- 使用梯度裁剪、优化器调整等方法稳定训练过程。
- 损失函数与评估指标:
- 合理选择损失函数和评估指标,确保它们能准确反映模型性能。
- 定期检查训练集和验证集上的表现,防止过拟合或欠拟合。
- 超参数调优:
- 利用网格搜索、随机搜索或贝叶斯优化等方法,系统地调整学习率、批量大小、层数等超参数,以找到最佳配置。
- 可视化分析:
- 通过特征图、权重矩阵、激活分布等可视化手段,直观理解模型行为,发现潜在问题。
- 日志记录与错误追踪:详细记录训练过程中的关键信息,包括损失值、准确率、超参数设置等,便于回溯分析。
调试策略
- 当一个机器学习系统效果不好时,通常很难判断效果不好的原因是算法本身,还是算法实现错误。由于各种原因, 机器学习系统很难调试。
- 在大多数情况下,我们不能提前知道算法的预期行为。事实上,使用机器学习的整个出发点是,它会发现一些我们自己无法发现的有用行为。如果我们在一个新的分类任务上训练一个神经网络,它达到 5 % 5\% 5% 的测试误差,我们没法直接知道这是期望的结果,还是次优的结果。
- 另一个难点是,大部分机器学习模型有多个自适应的部分。如果一个部分失效了,其他部分仍然可以自适应,并获得大致可接受的性能。
- 例如,假设我们正在训练多层神经网络,其中参数为权重 W \boldsymbol{W} W 和偏置 b \boldsymbol{b} b。
- 进一步假设,我们单独手动实现了每个参数的梯度下降规则。
- 而我们在偏置更新时犯了一个错误:
b ← b − α \boldsymbol{b}\gets \boldsymbol{b}-\alpha b←b−α — 公式1 \quad\textbf{---\footnotesize{公式1}} —公式1
其中, α \alpha α是学习率。这个错误更新没有使用梯度。它会导致偏置在整个学习中不断变
为负值,而这显然是错误的。然而只是检查模型的输出,该错误可能并不是显而易
见的。根据输入的分布,权重可能可以自适应地补偿负的偏置。
- 大部分神经网络的调试策略都是解决这两个难题的一个或两个。我们可以设计一种简单的情况,能够预见正确结果,判断和模型输出是否相符;我们也可以设计一个测试,检查神经网络实现的一部分。
- 一些重要的调试检测如下所列。
- 可视化模型的行为:
- 当训练模型检测图像中的对象时,查看一些模型检测到部分重叠的图像。
- 在训练语音生成模型时,试听一些生成的语音样本。
- 这似乎是显而易见的,但在实际中很容易只注意量化性能度量,如准确率或对数似然。
- 直接观察机器学习模型运行任务,有助于确定其达到的量化性能数据是否看上去合理。
- 错误评估模型性能可能是最具破坏性的错误之一,因为它们会使你在系统出问题时误以为系统运行良好。
- 可视化最严重的错误:
- 大多数模型能够输出运行任务时的某种置信度量。
- 例如,基于 softmax \text{softmax} softmax 函数输出层的分类器给每个类分配一个概率。
- 因此,分配给最有可能的类的概率给出了模型在其分类决定上的置信估计值。
- 通常,最大似然训练会高估正确预测的概率。
- 但是由于实际上模型的较小概率不太可能对应着正确的标签,因此它们在一定意义上还是有些用的。通过查看训练集中很难正确建模的样本,通常可以发现该数据预处理或者标记方式的问题。
- 例如,街景转录系统原本有个问题是,地址号码检测系统会将图像裁剪得过于紧密,而省略掉了一些数字。
- 然后转录网络会分配非常低的概率给这些图像的正确答案。
- 将图像排序,确定置信度最高的错误,显示系统的裁剪有问题。
- 修改检测系统裁剪更宽的图像,从而使整个系统获得更好的性能,但是转录网络需要能够处理地址号码中位置和范围更大变化的情况。
- 根据训练和测试误差检测软件:
- 拟合小数据集:
- 当训练集上有很大的误差时,我们需要确定问题是欠拟合,还是软件错误。
- 通常,即使是小模型也可以保证很好地拟合一个足够小的数据集。
- 例如,只有一个样本的分类数据可以通过正确设置输出层的偏置来拟合。
- 通常,如果不能训练一个分类器来正确标注一个单独的样本,或不能训练一个自编码器来成功地精准再现一个单独的样本,或不能训练一个生成模型来一致地生成一个单独的样本,那么很有可能是由于软件错误阻止训练集上的成功优化。
- 此测试可以扩展到只有少量样本的小数据集上。
- 比较反向传播导数和数值导数:
- 如果正在使用一个需要实现梯度计算的软件框架,或者在添加一个新操作到求导库中,必须定义它的 bprop \text{bprop} bprop 方法,那么常见的错误原因是没能正确实现梯度表达。
- 验证这些求导正确的一种方法是比较实现的自动求导和有限差分 (
finite difference
\text{finite difference}
finite difference) 计算的导数。因为:
f ′ ( x ) = lim ϵ → 0 f ( x + ϵ ) − f ( x ) ϵ f^\prime(x)=\lim\limits_{\epsilon\to 0}\displaystyle\frac{f(x+\epsilon)-f(x)}{\epsilon} f′(x)=ϵ→0limϵf(x+ϵ)−f(x) — 公式2 \quad\textbf{---\footnotesize{公式2}} —公式2
我们可以使用小的,有限的 ϵ \epsilon ϵ 近似导数:
f ′ ( x ) ≈ f ( x + ϵ ) − f ( x ) ϵ f^\prime(x) \approx \displaystyle\frac{f(x+\epsilon)-f(x)}{\epsilon} f′(x)≈ϵf(x+ϵ)−f(x) — 公式3 \quad\textbf{---\footnotesize{公式3}} —公式3
我们可以使用中央差分( centered difference \text{centered difference} centered difference)提高近似的准确率:
f ′ ( x ) = lim ϵ → 0 f ( x + 1 2 ϵ ) − f ( x − 1 2 ϵ ) ϵ f^\prime(x)=\lim\limits_{\epsilon\to 0}\displaystyle\frac{f(x+\displaystyle\frac{1}{2}\epsilon)-f(x-\frac{1}{2}\epsilon)}{\epsilon} f′(x)=ϵ→0limϵf(x+21ϵ)−f(x−21ϵ) — 公式4 \quad\textbf{---\footnotesize{公式4}} —公式4
扰动大小 ϵ \epsilon ϵ 必须足够大,以确保该扰动不会由于数值计算的有限精度问题向下近似太多。 - 通常,我们会测试向量值函数 g : R → R g:\mathbb{R}\to\mathbb{R} g:R→R 的梯度或 Jacobian \text{Jacobian} Jacobian矩阵。令人遗憾的是, 有限差分只允许我们每次计算一个导数。我们既可以运行有限差分 m n mn mn 次评估 g g g 的所有偏导数,又可以将该测试应用于一个输入输出都是 g g g 的随机投影的新函数。例如,我们可以用导数实现去测试函数 f ( x ) = u ⊤ g ( v x ) f(x)=\boldsymbol{u}^\top g(\boldsymbol{v}x) f(x)=u⊤g(vx),其中 u \boldsymbol{u} u 和 v \boldsymbol{v} v 是随机向量。正确计算 f ′ ( x ) f^\prime(x) f′(x) 要求能够正确地通过 g g g 反向传播,但是使用有限差分能够很有效地计算,因为 f f f 只有一个输入和一个输出。在多个 u \boldsymbol{u} u 值和 v \boldsymbol{v} v 值上重复这个测试通常是个好主意,可以减少测试忽略了垂直于随机投影的几率。
- 如果可以在复数上进行数值计算,那么使用复数作为函数的输入能有非常高效的数值方法估算梯度 (
Squire and Trapp, 1998
\text{Squire and Trapp, 1998}
Squire and Trapp, 1998)。该方法基于如下观察:
{ f ( x + i ϵ ) = f ( x ) + i ϵ f ′ ( x ) + O ( ϵ 2 ) — 公式5 real ( f ( x + i ϵ ) ) = f ( x ) + O ( ϵ 2 ) , image ( f ( x + i ϵ ) ϵ ) = f ′ ( x ) + O ( ϵ 2 ) — 公式6 \begin{cases} \begin{aligned} f(x+i\epsilon) &= f(x)+i\epsilon f^\prime(x)+O(\epsilon^2) &\quad\textbf{---\footnotesize{公式5}}\\ \text{real}(f(x+i\epsilon)) &= f(x)+O(\epsilon^2), \quad\text{image}(\frac{f(x+i\epsilon)}{\epsilon}) = f^\prime(x)+O(\epsilon^2) &\quad\textbf{---\footnotesize{公式6}} \end{aligned} \end{cases} ⎩ ⎨ ⎧f(x+iϵ)real(f(x+iϵ))=f(x)+iϵf′(x)+O(ϵ2)=f(x)+O(ϵ2),image(ϵf(x+iϵ))=f′(x)+O(ϵ2)—公式5—公式6
其中 i = − 1 i=\sqrt{-1} i=−1。和上面的实值情况不同,这里不存在 f f f 在不同点上计算差分消除影
响。因此我们可以使用很小的 ϵ \epsilon ϵ,比如 ϵ = 1 0 − 150 \epsilon=10^{-150} ϵ=10−150,其中误差 O ( ϵ 2 ) O(\epsilon^2) O(ϵ2) 对所有实用目标都是微不足道的。
- 监控激励函数值和梯度的直方图:
- 可视化神经网络在大量训练迭代后(也许是每个迭代)收集到的激励函数值和梯度的统计数据往往是有用的。
- 隐藏单元的预激励值可以告诉我们该单元是否饱和,或者它们平常的状态如何。
- 例如,对于整流器,它们多久关一次?是否有单元一直关闭?对于双曲正切单元而言,预激励绝对值的平均值可以告诉我们该单元的饱和程度。
- 在深度网络中,传播的梯度可以快速增长或快速消失,优化可能会受到阻碍。
- 最后,比较参数梯度和参数的量值也是有帮助的。
- 正如 ( Bottou, 2015 \text{Bottou, 2015} Bottou, 2015) 的建议,我们希望参数在一个 minibatch \text{minibatch} minibatch更新中变化的幅度是参数量值 1 % 1\% 1% 这样的级别,而不是 50 % 50\% 50% 或者 0.001 % 0.001\% 0.001%(这会导致参数移动得太慢)。
- 也有可能是某些参数以良好的步长移动,而另一些停滞。
- 如果数据是稀疏的(比如自然语言),有些参数可能很少更新,检测它们变化时应该记住这一点。
- 可视化模型的行为:
- 最后,许多深度学习算法为每一步产生的结果提供了某种保证。
总结
深度学习调试是一场耐心与智慧的较量,它要求开发者不仅要有扎实的理论基础,还要具备敏锐的洞察力和灵活应变的能力。通过上述调试策略的灵活运用,我们可以更加高效地诊断和解决模型训练中的问题,推动深度学习技术在各个领域的应用不断向前发展。