当我们使用 read() 和 write() 系统调用向内核提交读写文件操作时,内核并不会立刻向硬盘发送 I/O 请求,而是先将 I/O 请求交给 I/O 调度层进行排序和合并处理。经过 I/O 调度层加工处理后,才会将 I/O 请求发送给块设备驱动进行最终的 I/O 操作。
下图是块设备 I/O 栈的架构图:

什么是 I/O 调度层
现实中块设备的种类非常多,如磁盘、SSD(固态硬盘) 和 CD-ROM 等。由于不同种类的块设备其物理结构不同,所以优化 I/O 效率的算法也不一样。如:SSD 读写任意地址中的数据速度都一样,所以就没必要进行额外的优化,只需要将用户提交 I/O 操作直接发送给块设备驱动即可。
但有些块设备的物理结构比较特殊,如磁盘,其读写速度与磁头移动的距离(寻道)有关,所以磁头移动的距离越远,读写速度就越慢。
磁盘的物理结构如下图所示:

对于磁盘来说,顺序读写的速度是最快的。这是由于顺序读写时,磁头移动的距离最小。所以,避免随机读写是加速磁盘 I/O 效率最有效的办法。
假如有3个进程先后向磁盘写入数据,如下图所示:

如上图序号的顺序所示:首先进程 A 向扇区 A 写入数据,然后进程 B 向扇区 B 写入数据,最后进程 C 向扇区 C 写入数据。
如上图所示,扇区 A 到扇区 B 的距离要比扇区 A 到扇区 C 的距离远。如果按照 I/O 提交的顺序进行操作,那么步骤如下:
- 当进程 A 的数据写入到扇区 A 后,将磁头移动到较远的扇区 B 处,并将进程 B 的数据写入到扇区 B。
- 当进程 B 的数据写入到扇区 B 后,将磁头倒退回到扇区 C 处,并将进程 C 的数据写入到扇区 C 中。
聪明的读者可以发现,其实上面的过程可以进行优化。而优化的方案是:进行 I/O 操作时,按照磁盘的移动方向的顺序进行 I/O 操作,而不是按照提交的顺序进行 I/O 操作。
如上述例子中,将数据写入到扇区 A 后,应该接着写扇区 C,最后才写扇区 B。因为这样磁盘移动的距离最小,寻道所需的时间最小。
为了提高 I/O 操作的效率,Linux 内核需要对用户提交的 I/O 操作进行排序和合并,这个工作就是通过 I/O 调度层来完成。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
I/O 调度层工作原理
通过前面的分析可知,I/O 调度层的主要工作是合并和排序用户提交的 I/O 操作,从而达到提升 I/O 效率的作用。
由于不同的场景或硬件所需的优化手段不一样,比如固态硬盘(SSD)就不需要对 I/O 请求进行排序。
Linux 内核为了适配不同的场景或硬件,定义了一套统一的接口。不同的 I/O 调度算法,只需要实现这套接口即可无缝接入到 I/O 调度层。如下图所示:

从上图可知,Linux 内核支持多种 I/O 调度算法,如:CFQ调度算法、Deadline调度算法 与 noop调度算法 等。我们可以根据不同的场景来选择适当的调度算法,从而提升 I/O 操作的效率。
I/O 调度层通过 elevator_ops 结构体来适配不同的 I/O 调度算法,这个结构体定义了一系列的接口。不同的 I/O 调度算法只需要实现这些接口,然后注册到 I/O 调度层后,即可被 I/O 调度层识别。
elevator_ops 结构体定义如下:
struct elevator_ops
{
elevator_merge_fn *elevator_merge_fn;
elevator_merged_fn *elevator_merged_fn;
...
elevator_dispatch_fn *elevator_dispatch_fn;
elevator_add_req_fn *elevator_add_req_fn;
...
};elevator_ops 结构定义了很多接口,但 I/O 调度算法只需要按需实现其中部分重要的接口即可。
下面我们来介绍一下 elevator_ops 结构几个重要接口的作用:
- elevator_merge_fn:用于判断新提交的 I/O 请求是否能够与 I/O 调度器中的请求进行合并。
- elevator_merged_fn:用于对合并后的 I/O 请求进行重新排序。
- elevator_dispatch_fn:用于将 I/O 调度器中的 I/O 请求分发给块设备驱动层。
- elevator_add_req_fn:用于向 I/O 调度器添加新的 I/O 请求。
由于内核支持多种 I/O 调度算法,所以内核通过链表把所有的 I/O 调度算法连接起来。如果用户编写了新的 I/O 调度算法,可以使用 elv_register() 函数将其注册到内核中。
Deadline 调度算法
上面介绍了 I/O 调度层的原理,现在我们通过 Deadline调度算法 来分析它是怎么提升 I/O 操作的效率的。
1. 排序队列
Deadline 调度算法通过使用红黑树(一种平衡二叉树)来 I/O 请求进行排序,节点的键为 I/O 请求的开始扇区号,值为 I/O 请求实体。如下图所示:
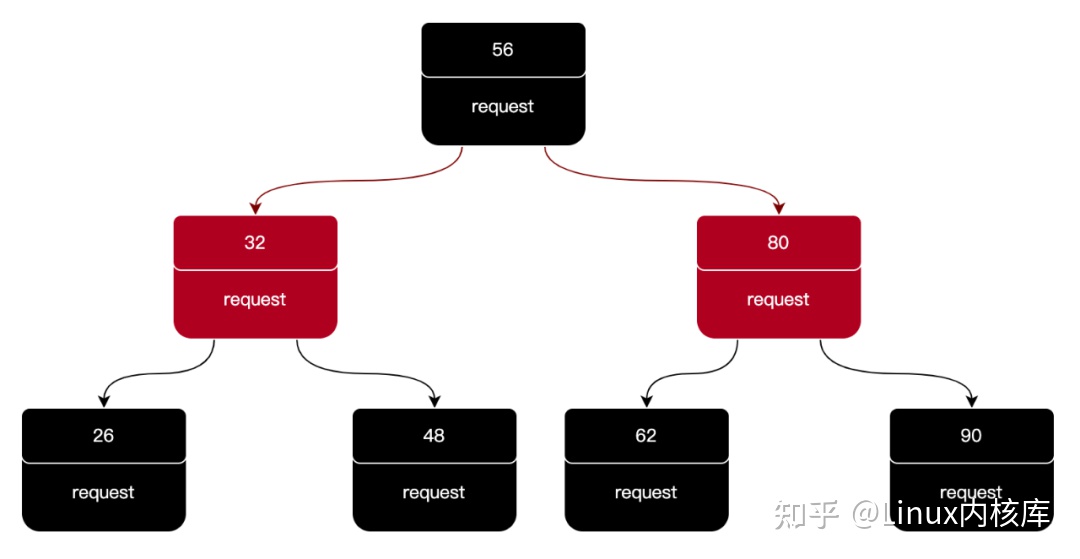
当向设备驱动层分发 I/O 请求时,Deadline 调度器会按照排序后的顺序进行分发,这样做的好处是:可以减少磁头移动的距离。如下图所示:
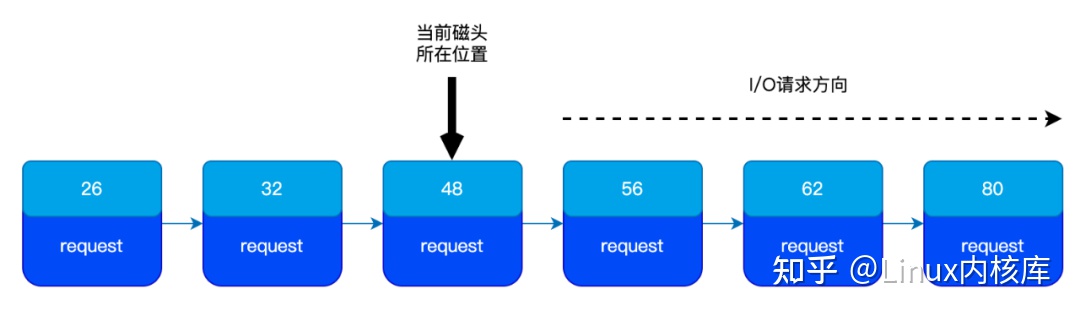
虽然这样能够减少磁头移动的距离,但对 I/O 请求进行排序可能会导致某些 I/O 请求出现 饥饿 的情况,饥饿的意思是用户指发送的 I/O 请求长时间得不到执行。
试想一下以下场景:
磁盘正在扇区号 100 处执行 I/O 操作,这时用户提交一个新的 I/O 请求,此 I/O 请求的起始扇区号为 200,如下图所示:

如果用户没有提交新的 I/O 请的话,那么执行完扇区号 100 处的 I/O 请求后,便会移动到扇区号 200 处执行 I/O 请求。
此时如果用户连续在扇区号 110、120、130 处提交了新的 I/O 请求,由于 Deadline 调度器会以 I/O 请求的起始扇区号进行排序,所以 I/O 队列将会变成如下图所示情况:
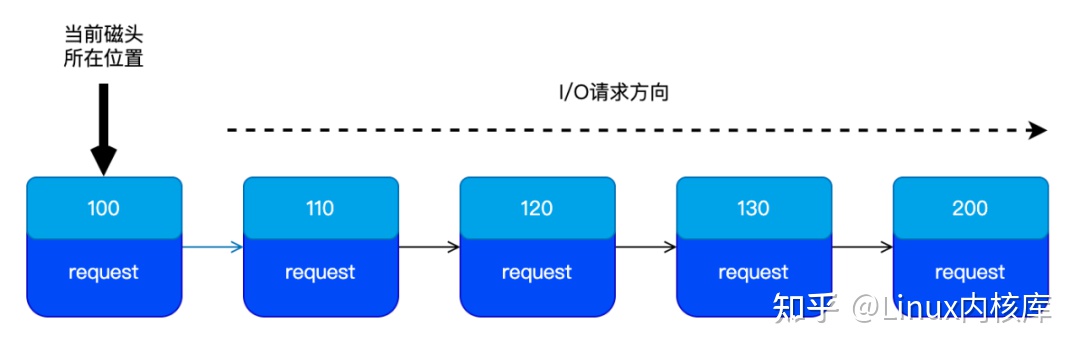
执行 I/O 请求时会按照排序后的顺序进行操作,那么扇区号 200 处的 I/O 请求就很有可能出现饥饿的情况。
2. FIFO队列
为避免 I/O 请求出现饥饿的情况,Deadline 调度器还使用 FIFO(Frist In Frist Out)队列来管理 I/O 请求。
在新的 I/O 请求被提交到 Deadline 调度器时,Deadline 调度器会为 I/O 请求设置一个限期(Deadline),然后添加到 FIFO 队列中。如下图所示:

在向设备驱动层分发 I/O 请求时,Deadline 调度器首先会查看 FIFO 队列中的第一个 I/O 请求是否超时。如果超时了,那么将 FIFO 队列的第一个 I/O 请求分发给设备驱动层。否则,将会从排序队列中获取下一个 I/O 请求分发给设备驱动层。
Deadline 调度器通过设置 I/O 请求的限期和 FIFO 队列,来解决 I/O 请求出现饥饿的情况。
另外,Deadline 调度器为 读/写 操作分别各分配一个排序队列和 FIFO 队列,所以在 Deadline 调度器中维护了 4 个队列:读排序队列、写排序队列、读FIFO队列 和 写FIFO队列。
这是因为在 I/O 操作中,读操作比写操作需要的实时性更高,所以会优先处理读操作。如果将读写操作放在同一个队列进行管理,那么就不能优先处理读操作了。